Michael Brown
Nov 24, 2017 • 5 min read
より良い形でお客様のニーズを満たす方法を見つけながら、コードの改善点を発見した記録です
ホスティングサービスを運営する際には、何が起きているかを把握することが不可欠です。マクロスケール(パフォーマンスグラフ)とマイクロスケール(リクエストログ)の両方において、環境への可視性が求められます。それらのリクエストログを分析することで、全体像では見えにくい詳細を把握することができます。
Discourseの利用方法という観点で、いくつかの外れ値となるお客様がいらっしゃいます。そうしたお客様のデータサイズは、私たちが予期しない方向(例えば数百万人のユーザーや大量のカテゴリ)に拡大することがあります。私たちは、APIを通じてコストの高いリクエストを大量に送信することで意図せず自分たちのサービスをDOS状態にしてしまわないよう、お客様と連携して対応してきました。しかし、特定の方法でリソースを過負荷にさせてしまったことへの対応として、サイトのAPIキーを一時的に無効化せざるを得ないケースもありました。これは侵襲的な対応であり、私たちとしては望ましくありません。本来あるべき姿よりも対応が遅れていると考えています。
ある特定のお客様とAPIの利用状況について話し合っていた際、次のような質問を受けました。
何が起きたのかをより詳しく理解できるよう、詳細情報(例:時間帯、リクエスト数、APIキーごとのリクエスト数、リクエストされたエンドポイントなど)を提供していただくことは可能でしょうか?
これは私たちに対するごく当然の質問であり、Kibanaを使えば簡単に答えを提供することができます!ここでは、その方法を一緒に見ていきましょう。
リクエストに関する通常の情報(ホスト名、リモートIP)に加えて、Discourseのバックエンドは使用されたEmberルートとCPU処理時間をレスポンスヘッダーに付加します。
X-Discourse-Route: list/latestX-Runtime: 0.370071
これらはその後、フロントエンドのhaproxyによってキャプチャされます。結果として得られたデータはlogstashに送られ、そこで加工されてElasticsearchにドキュメントとして投入されます。この情報をElasticsearchで持てるのは素晴らしいことですが、数百万件のログエントリがある場合、次のステップはどうすればよいでしょうか?どのように分析しますか?何を探しますか?
まず、新しいビジュアライゼーションを作成し、1日分のデータ全体(実際には、あるホスティングセンターのデータのサブセット)を対象に作業します。
最初の画面はあまり興味深くはありませんが、syslogエントリ、nginxログ、アプリケーションログ、haproxyログを含む2億7900万件のドキュメントを集計しています。次のフィルターを使って少し絞り込んでみましょう。
_exists_:response_header_discourse_route
こうすることで、実際にアプリケーションに到達したリクエストに関連するドキュメントだけを確認できます。同時に、X-Runtimeヘッダーの値(単位はミリ秒)に対して統計分析を行うメトリクスをいくつか追加して、洞察を得られるようにしましょう。
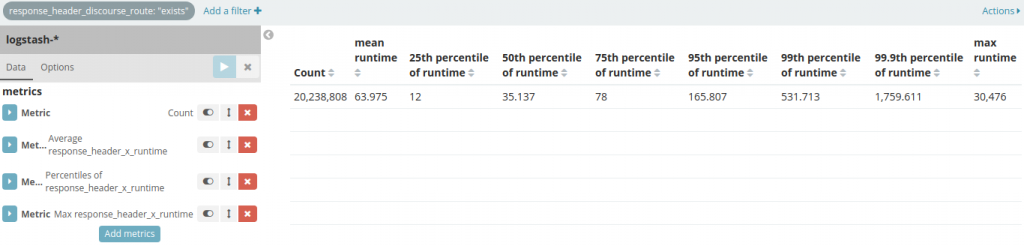
当然ながら、すべてを混在させたままでは意味がないため、この時点でディメンションに沿って統計を集計する(SQLユーザーの方には、これはGROUP BYに相当します)ことが合理的です。これにより、リクエストの種類によるばらつきを明らかにします。
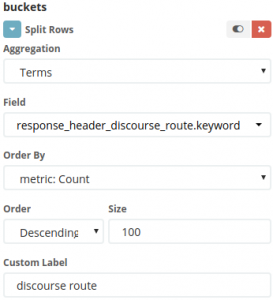
ここで、それらのリクエストについて興味深いことが見えてき始めます。
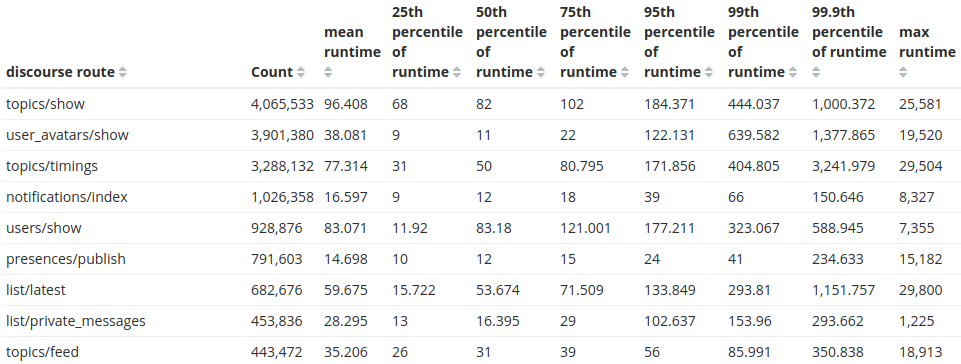
予想通り、Discourseへの最も一般的なリクエストはトピックの表示です。素晴らしい!しかし、特定のお客様に関する情報を見つけるという本来のミッションに集中して掘り下げていきましょう。検索対象をそのお客様のサイトのみに絞り込み、ルートごとの合計実行時間という新しいメトリクスを追加しました。
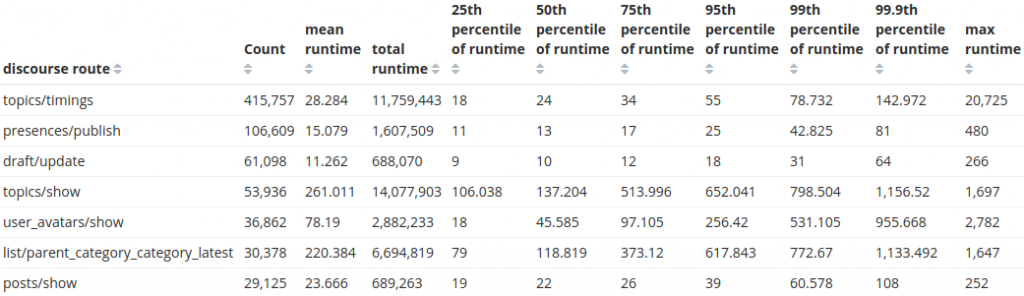
APIキーを持つリクエストのみに絞り込むと、お客様からの質問に対する答えにたどり着きます。
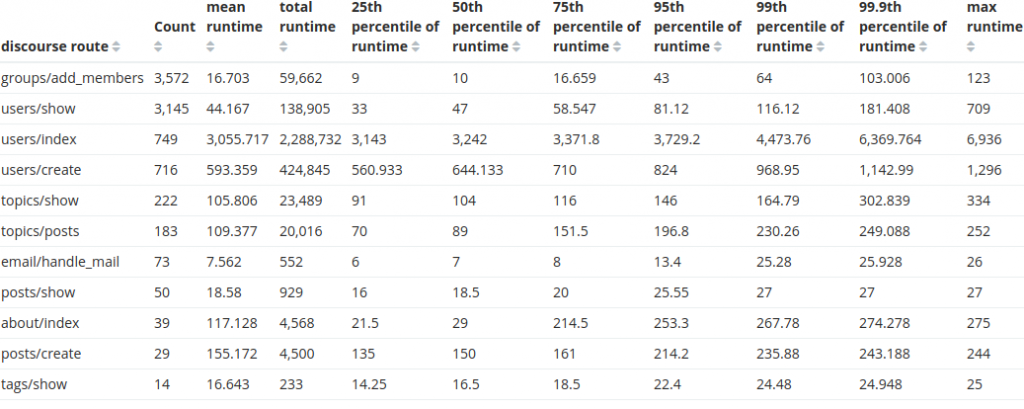
その外れ値ルートであるusers/indexルートは、 常に コストが高い ものです。おそらくそこには改善の余地があるでしょう。他のお客様にとってはどの程度コストがかかっているのでしょうか?
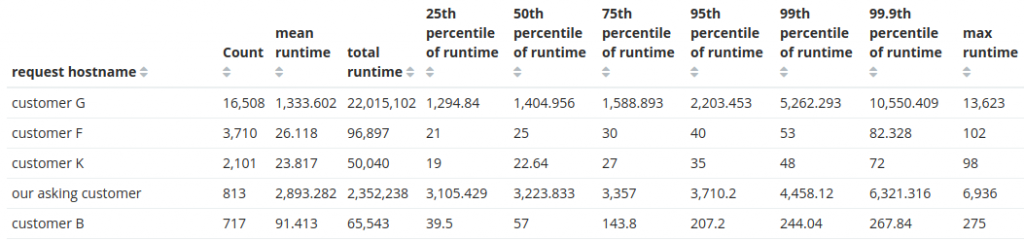
お客様Gのこの単一APIルートに対するリクエストを処理するだけで、1日あたり6時間ものCPU時間を消費しています。一体何が起きているのか、そしてなぜこれほどコストが高いのでしょうか?
少し調べてみると、users/indexルートは管理者限定のルートで、ユーザー名とメールアドレスによるフィルタリングでユーザーを検索する機能を担っていることがわかりました。これを完了するためには、2回のフルテーブルスキャンが必要です。問い合わせを行ったお客様はシステム内に非常に多くのユーザーを抱えており、それがこの特定のクエリに負荷をかけていたのです。
このルートが頻繁に呼び出されていた(しかも非常にコストが高かった)という事実から、私たちはそれがなぜ使われているのかを調査することになりました。調べてみると、私たちのAPIにギャップがあることがすぐに判明しました。お客様が、私たちの設計では満たされていないニーズを持っていたのです。そのワークフローはおおよそ次のようなものです。
- ユーザー詳細を同期する
- メールアドレスでユーザーを検索する:
https://discourse.CUSTOMER.com/admin/users/list/active.json?api_key=KEY&api_username=sync&email=USER@aol.com - 返されたユーザーの中から、メールアドレスが完全一致するユーザーを特定する
- そのユーザーに対して操作を実行する(例:グループへの追加・削除、ユーザー情報の更新)
私たちはAPIを2つの方法で修正することでこれに対応しました。
- 列インデックスを使用してロジックをショートカットする:メール列に完全一致がある場合は、そのユーザーのみを返す(コミット)
- 完全なメール一致のみをリクエストし、それ以外には関心を持たない新しいAPIコールを追加する(コミット)
これらの変更(結果的には、主に2番目の変更)により、これらのクエリにかかる時間が大幅に短縮されました。
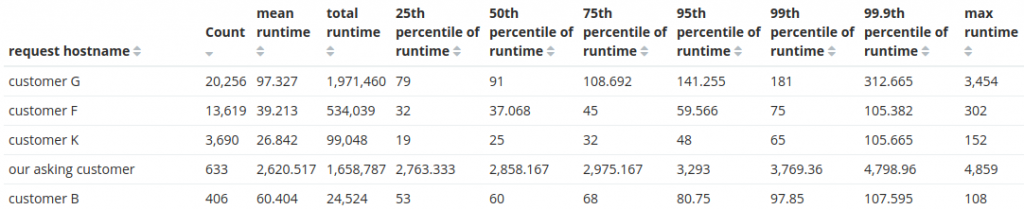
お客様Gがフィルターとしてemail=を使用するように切り替えてからのAPIコール処理において、1日あたり5.5CPU時間以上の節約、つまり単一サイトだけで92.3%という驚異的な削減を達成することができました。
Elasticsearchスタックについては、https://www.elastic.coでさらにお読みいただけます。
Jamie Riedeselさんに多大な感謝を申し上げます。彼女のGetting started with Logstashに関する記事を読んだことで、インジェストパイプラインの理解が深まりました。
原文はこちら:
Good Loopでは、Discourseのセルフホスティングを安価で提供しています。開発元であるCDCK社の協力のもと、公式ブログ記事の翻訳・公開など、日本での普及にも努めています。