Michael Fitz-Payne
Oct 5, 2021 • 8 min read
複雑なアプリケーションやホスティング環境の中で、セグフォルトはさまざまな奇妙で多様な症状として現れることがあります。Discourseアプリケーションにとっては、通知メールの送信失敗、アップロードされた画像の最適化失敗、あるいはその他の気づきにくい問題として現れることがあります。
場合によっては、セグフォルトによるプログラムのクラッシュを引き起こす微妙なバグは、サービス運用に組み込まれたフォールトトレランス(例えば、コンテナが終了時に自動的に再起動されるなど)によって必ずしも明らかにならないことがあります。これが、セグフォルトの原因を特定・追跡し、誰かがセグフォルトによるサービス障害に気づくまでそれらの奇妙な症状が残り続けることを防ぐために、モニタリングが重要である理由です。
SIGSEGVの解剖
セグフォルトとは何かについて、もう少し詳しく説明するのが良いでしょう。POSIX.1によると、セグフォルト(セグメンテーションフォルト)は、プログラムが無効なメモリ参照を生成した際に発生するシグナル(SIGSEGV)です。問題を起こしたプロセスにはSIGSEGVがシグナルとして送られます。SEGVという名前は「segmentation violation(セグメンテーション違反)」の略です。
以下は、Cで書かれたLinuxシステム上でセグフォルトを引き起こす不正な操作の例です。この例はnilポインタの逆参照によって引き起こされます。
#include <stddef.h>
int main(int argc, char *argv) {
const char *msg = NULL;
char c = *msg; // dereference of NULL pointer
}
プログラムを実行してみましょう。
$ gcc -O0 segfault.c -o segfault
$ ./segfault
Segmentation fault (core dumped)
この種のセグフォルトは、Cのようにメモリポインタを直接扱うプログラムを書く際に非常に起こりやすいです。DiscourseアプリケーションのバックエンドはRubyで書かれており、多くのRuby gemにはCで書かれた拡張機能が含まれています。非常に慎重なメモリ管理を行っていても、特定の条件下でセグフォルトを意図せず引き起こすバグが混入することはあり得ます。
SIGSEGVは、プロセスの終了とコアの保存(コアについては次で詳述します)を引き起こすいくつかのシグナルの一つです。シグナルハンドラでこのシグナルをキャッチすることは可能ですが、通常、プロセスが回復して正常な動作に戻るための安全な方法はありません。
その理由の一つは、シグナルハンドラから戻る際に、プロセスはシグナルによって中断される前に実行していた同じ地点から再開されるためです。セグメンテーションフォルトの場合、これは通常、同じシグナルが再び生成され、シグナルハンドラが再び呼び出されるという繰り返しをもたらします。
ただし、シグナルハンドラを使用して、プログラムを終了する前にディスク上のファイルなどの一時リソースをクリーンアップすることは可能です。シグナルハンドラ内で安全に呼び出せる関数は、POSIX.1で定義された非同期シグナル安全(async-signal-safe)な関数のサブセットのみです。詳細についてはsignal-safety(7)を参照してください。なお、unlink(2)は非同期シグナル安全として記載されています。
フォルトのコアを掘り下げる
コアには、カーネルによる終了時のプロセスのメモリダンプが含まれています。コアに含まれる実際のデータはプラットフォームによって異なりますが、Linuxではデフォルトで以下のメモリが含まれます:
Dump anonymous private mappings.
Dump anonymous shared mappings.
Dump ELF headers.
Dump private huge pages.
お使いのプラットフォームに関する情報はcore(5)マニュアルで確認できます。Linuxではコアファイルはデフォルトでプロセスの現在の作業ディレクトリに保存されます。
コアを生成するシグナルはいくつかあります。以下はsignal(7)からのリストです(一部の情報は省略しています):
Signal Comment
──────────────────────────────────────────────────
SIGABRT Abort signal from abort(3)
SIGBUS Bus error (bad memory access)
SIGFPE Floating-point exception
SIGILL Illegal Instruction
SIGIOT IOT trap. A synonym for SIGABRT
SIGQUIT Quit from keyboard
SIGSEGV Invalid memory reference
SIGSYS Bad system call (SVr4);
ee also seccomp(2)
SIGTRAP Trace/breakpoint trap
SIGUNUSED Synonymous with SIGSYS
SIGXCPU CPU time limit exceeded (4.2BSD);
ee setrlimit(2)
SIGXFSZ File size limit exceeded (4.2BSD);
Linuxカーネルらしく、コアファイルに対して行われることに関する多くのオプションを設定するための方法があります。例えば、コアに保存されるメモリセグメント、ファイルサイズの制限、コアを保存する場所、名前の付け方など、その他多数があります。ここでは、コアをユーザー定義プログラムに送信するためのカーネルの設定と、Discourseのホスティングでインフラ全体で発生するセグフォルトを監視するためにこれをどのように活用したかに焦点を当てます。
Linux 2.6以降、カーネルはprocファイルシステムの/proc/sys/kernel/core_pattern(またはsysctl kernel.core_pattern)に設定を公開しており、これを使用してコアファイルの名前付け方法を変更できます。この機能はLinux 2.6.19で拡張されました。
core(5)マニュアルより:
Piping core dumps to a program
Since kernel 2.6.19, Linux supports an alternate syntax for the /proc/sys/kernel/core_pattern
file. If the first character of this file is a pipe symbol (|), then the remainder
of the line is interpreted as the command-line for a user-space program (or script)
that is to be executed.
これはさまざまな方法で活用できます!私たちの場合、この機能をセグフォルトの監視に使用したいと考えていました。ソリューションがコンテナ化されたプロセスと初期ネームスペースで動作するプロセスの両方に対応する必要があることが重要でした。
ありがたいことに、これは以下のとおり実現可能です:
The process runs in the initial namespaces (PID, mount, user, and so on) and
not in the namespaces of the crashing process.
最終的に使用したcore_patternと、コアを処理するシンプルなプログラムを見てみましょう。
$ cat /proc/sys/kernel/core_pattern
|/usr/local/sbin/process-core %h %s %E
各コンポーネントの説明:
- 最初の部分
|/usr/local/sbin/process-coreは、カーネルが実行してstdin経由でコアを送信するユーザースペースプログラムを指定します。最初の文字が|であり、これがカーネルに/usr/local/sbin/process-coreがユーザースペースプログラムであることを伝えます。 - お察しのとおり、
%h %s %Eは実行時に置き換えられるテンプレートの指定子です:
%h Hostname (same as nodename returned by uname(2)).
%s Number of signal causing dump.
%E Pathname of executable, with slashes ('/') replaced by exclamation marks ('!') (since Linux 3.0).
- ホスト名
%hを使用して、セグフォルトが発生したホストを特定できます。また、コンテナのホスト名は保持されるため、セグフォルトが発生したコンテナも特定できます。 - シグナル番号
%sは重要です。前述のとおり、コアを生成するシグナルは複数あり、特定のシグナルに対してのみアラートを発生させたいためです。 - 実行ファイルのパス名は、プロセスが終了した際に何が動作していたかを絞り込む最後の情報です。順序は重要であり、実行ファイルのパス名は5.3.0より古いカーネルではスペースを含む可能性があります。
process-coreスクリプトはここには含めませんが、非常にシンプルです:
- stdinストリームをディスク上のファイルにコピーする
- Prometheusの4タプル(ホスト名、プログラム名、シグナル、コアの存在)のカウンターメトリクスをインクリメントする
セグフォルトが現れた!
私たちはインフラ全体の監視に、非常に強力で柔軟なツールであるPrometheusとAlertmanagerを幅広く活用しています。上記のメトリクスを使用したセグフォルトプロセスのアラートは、coredump_process_count{signal=~"SEGV|ABRT"} > 0のようになります。言い換えれば、「SEGVまたはABRTシグナルを受信したメトリクスが存在する場合、このアラートを発火する」ということです。
このアラートを最初に実装したとき、何が起こるかわかりませんでした。結局、プログラムがクラッシュしているのに気づかないことが実際にどのくらいあるのでしょうか?最初は数日間アラートが発火しませんでした……しかし、突然短期間で多数(50件)のアラートが発火し、何かが起きていることがわかりました。
原因の絞り込み、実際の例
Discourseでは、すべてのアラートを社内のDiscourseフォーラム経由で受け取っています。これはチームとして発生したアラートについて協力して対応できるため、私たちにとって理想的なワークフローです。また、すべての種類のアラートの履歴記録を保持しており、将来の問題のデバッグに非常に役立ちます。
以下は、前述のセグフォルト問題に関するアラートトピックの例です:
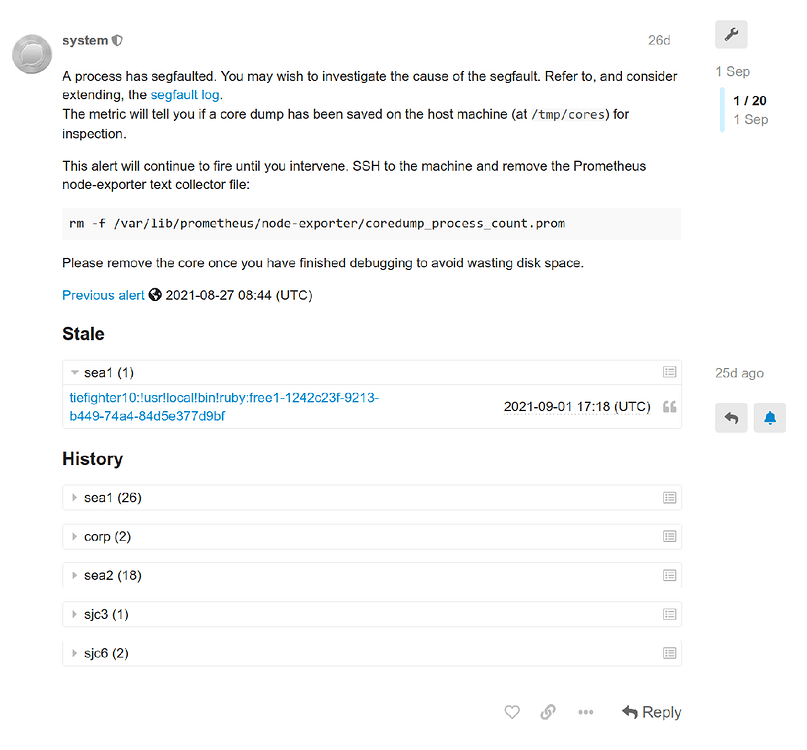
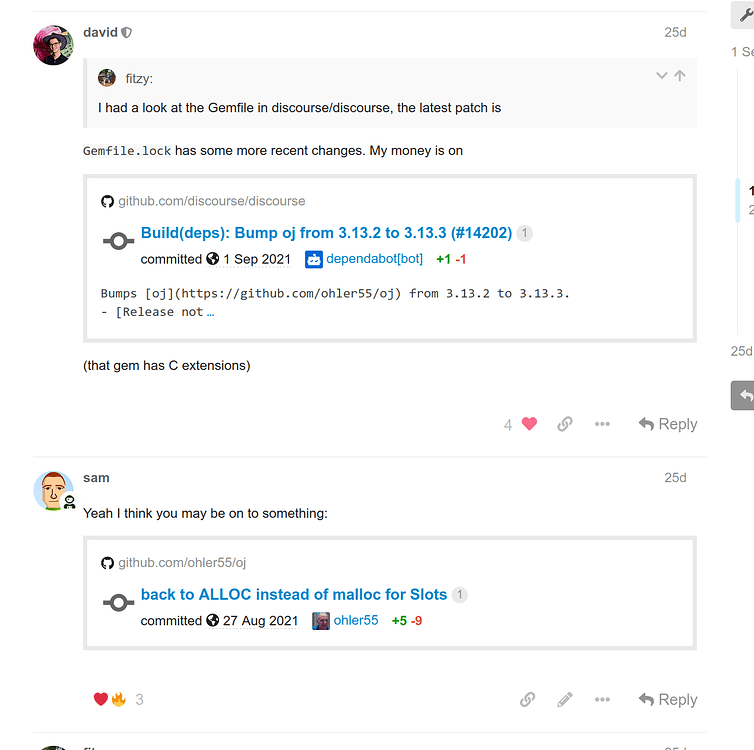
まず確認したのは、アラートを発火させているプロセスが何かということでした。この場合、メトリクスは問題のプロセスとして!usr!local!bin!rubyを報告していました。その情報とホスト名がアプリケーションコンテナのものであることから、セグフォルトがアプリケーションのどこかから来ていることは明らかでした。変更履歴を調べると、目立った原因として一部のgem依存関係のバンプのみがありました。gemにはCの拡張機能が含まれることが多いため、これは怪しくなってきました。
gemの変更をロールバックしてデプロイした後、セグフォルトのアラートは発火しなくなりました。この時点で問題が解決されたことには満足していましたが、上流のメンテナーへのより有益なissueレポートのために、もう一歩踏み込んでデバッグしたいと考えました。
コアダンプにアクセスできたため、セグフォルトの発生源をデバッグするためにgdbという魔法のようなツールを使用しました。コアをデバッグするには、クラッシュしたプロセスが動作していた環境(gemやCの拡張機能などのリソースを含む)に近い環境内でRubyをgdbの下で実行する必要があります。
これは、gdbがインストールされ、コアファイルがコンテナ内にコピーされた、Rubyプロセスが動作していたイメージに基づくコンテナ内で行うことができます:
# Inside the container for debugging
root@2dc12f5358fb:/# apt update && apt install --yes gdb
root@2dc12f5358fb:/# gdb $(which ruby) corefile
gdbを機能させるには、コンテナにSYS_PTRACEケーパビリティが必要であり、実行時に--cap-add=SYS_PTRACEで追加できます。
これが読み込まれると、(gdb)プロンプトが表示されます。通常はバックトレースが必要であり、btコマンドで出力できます。長いバックトレースの一部のみを掲載します:
(gdb) bt
#0 __GI_raise (sig=sig@entry=6) at ../sysdeps/unix/sysv/linux/raise.c:50
#1 0x00007fbe5f3ed535 in __GI_abort () at abort.c:79
#2 0x00007fbe5f9d375b in die () at error.c:664
#3 rb_bug_for_fatal_signal (default_sighandler=0x0, sig=sig@entry=11, ctx=ctx@entry=0x7fbe12011ac0, fmt=fmt@entry=0x7fbe5fc69f8b "Segmentation fault at %p") at error.c:664
#4 0x00007fbe5fb9243b in sigsegv (sig=11, info=0x7fbe12011bf0, ctx=0x7fbe12011ac0) at signal.c:946
#5 <signal handler called>
#6 locking_intern (c=0x7fbe5952f710,
key=0x7fbddd93607e "wiki\":false,\"reviewable_id\":null,\"reviewable_score_count\":0,\"reviewable_score_pending_count\":0,\"topic_posts_count\":2,\"topic_filtered_posts_count\":2,\"topic_archetype\":\"regular\",\"category_slug\":\"android"..., len=4) at cache.c:210
#7 0x00007fbe5f0640aa in oj_calc_hash_key (pi=<optimized out>, parent=<optimized out>) at strict.c:47
セグフォルトはoj_calc_hash_key関数で発生しているようです。OJはRuby用の最適化されたJSONパーサーであり、先ほどのアラートを引き起こしたと思われるgem更新のロールバックリストに含まれていました。
このデバッグにより、このissueレポートが作成され、修正はわずか数日後にマージされました。OJメンテナーによる非常に迅速な対応でした!
ツールが実装されてアラートシステムに統合されていなければ、このセグフォルトの症状はおそらく気づかれないままになっていたか、セグフォルトが発生していた場所のために何日もの激しい頭を悩ませる状況になっていたでしょう。その代わりに、私たちは数時間以内に問題を特定し、修正を展開することができました。
これは、Discourseにおいて、インフラ上で動作する内部サービスを綿密に監視し、アラートが発生した際に迅速に対応することがいかに重要であるかを改めて示してくれています。また、私たちが恩恵を受けている多くのオープンソースプロジェクトにフィードバックを提供し、貢献できることも素晴らしいことです。
リンクと参考資料
- signal-safetyマニュアル
- unlinkマニュアル
- coreマニュアル
- signalマニュアル
- Advanced Programming in the UNIX Environment(別名UNIX programming bible)
原文はこちら:
Good Loopでは、Discourseのセルフホスティングを安価で提供しています。開発元であるCDCK社の協力のもと、公式ブログ記事の翻訳・公開など、日本での普及にも努めています。